ML 모델을 서비스에 적용하려고 하면 일반적으로 느린 속도 때문에, 인퍼런스 속도를 높이기 위한 방법도 많이 고민하게 됩니다.
그래서 오늘은 ONNX(Open Neural Network eXchange)를 한번 소개해보려고 합니다.
ONNX
onnx는 머신러닝 모델 공개 표준을 목표로 개발된 오픈소스입니다.
Tensorflow, Pytorch는 물론이며 이 외에도 다양한 툴에서 사용할 수 있도록 지원됩니다.
특히, 파이썬 환경 뿐만 다른 언어를 활용할 수도 있으며 모델을 변환하면서, 그래프를 최적화하여 연산 속도 개선 효과도 있습니다.
바로 코드로 넘어가보도록 하겠습니다.
오늘도 학습은 논외니까 pretrained model 중에 torchvision에서 가장 기본 모델인 resnet을 활용하겠습니다.
모델 변환
import torch
import torchvision.models as models
model = models.resnet18(pretrained=True)
model.eval()
dummy_input = torch.randn(1, 3, 224, 224)
torch.onnx.export(model, dummy_input, "resnet18.onnx")먼저 torchvision의 models를 활용하여 pretrained resnet18 모델을 초기화합니다.
서빙을 위한 모델이라고 생각하고 dropout을 제거하기 위해서 model.eval()을 실행해주었습니다.
onnx 변환은 torch.onnx를 활용하는데 이 때, 사용할 input size에 맞춰서 dummy_input을 넣어주어야 합니다.
여기서는 (1, 3, 224, 224) 사이즈로 생성해주었습니다. 참고로 1은 배치 사이즈, 3은 rgb 채널, 224*224는 이미지 크기입니다.
모델 확인
import onnx
model = onnx.load("resnet18.onnx")
print(onnx.helper.printable_graph(model.graph))변환된 모델을 onnx 라이브러리를 활용하여 한번 확인을 해보겠습니다.
onnx.helper.printable_graph로 모델의 그래프를 출력해보면 아래와 같은 모델의 layer 정보가 출력됩니다.
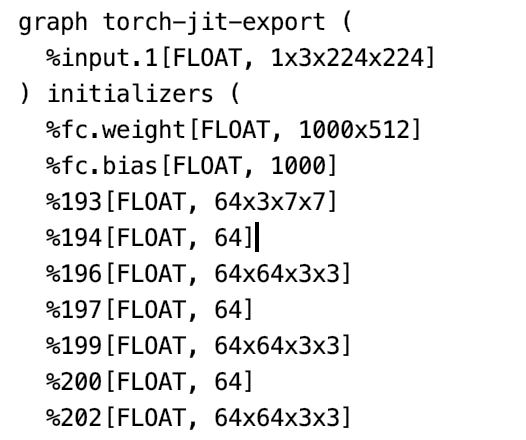
모델 추론
onnx를 활용하여 inference 할 때는 onnxruntime이란 라이브러리를 활용합니다.
import numpy as np
import onnxruntime as ort
ort_session = ort.InferenceSession("resnet18.onnx")
outputs = ort_session.run(None, {"input.1": np.random.randn(1, 3, 224, 224).astype(np.float32)})
print(outputs)InferenceSession을 활용하여 모델을 불러오고, run 명령을 실행하면 됩니다.
run 명령을 실행할 때 inference의 output과 input에 대하여 dictionary 형태로 입력을 넣어주어야 합니다.
output에는 None을 넣으면 모든 output이 출력이 됩니다.
input을 넣어줄 때는 위에서 확인한 그래프의 input layer의 이름을 활용하여 위와 같이 넣어주시면 됩니다.
모델 추론 결과 비교
모델이 잘 변환되었고 이상이 없는지 테스트를 하기 위해서는 onnxruntime으로 추론한 결과와 torch model로 추론한 결과를 비교해보아야 합니다.
import torch
import torchvision.models as models
import numpy as np
import onnxruntime as ort
dummy_input = torch.randn(1, 3, 224, 224)
model = models.resnet18(pretrained=True)
model.eval()
torch_output = model(dummy_input)
ort_session = ort.InferenceSession("resnet18.onnx")
ort_outputs = ort_session.run(None, {"input.1": dummy_input.numpy()})
np.testing.assert_allclose(torch_output.detach().numpy(), ort_outputs[0], rtol=1e-03, atol=1e-05)dummy_input을 생성하고 torch, onnxruntime으로 각각 추론을 위와 같이 진행한 다음에 np.testing.assert_allclose를 활용하여 비교를 해주었습니다.
onnxruntime으로 변환하면서 모델을 변환하는 과정에서 계산이 아주 약간 달라지기 때문에 rtol, atol로 오차 범위를 지정하여 확인합니다.
마지막 라인 실행 결과에서 아무것도 출력되지 않는다면, 테스트를 성공한 것 입니다.
성능 테스트
onnxruntime을 활용하여 성능이 정말로 빨라지는지 확인해보겠습니다.
import time
import torch
import torchvision.models as models
import numpy as np
import onnxruntime as ort
dummy_input = torch.randn(1, 3, 224, 224)
model = models.resnet18(pretrained=True)
model.eval()
torch_output = model(dummy_input)
start = time.time()
for _ in range(1000):
torch_output = model(dummy_input)
print("torch inference:", time.time() - start)
ort_session = ort.InferenceSession("resnet18.onnx")
ort_outputs = ort_session.run(None, {"input.1": dummy_input.numpy()})
start = time.time()
for _ in range(1000):
ort_outputs = ort_session.run(None, {"input.1": dummy_input.numpy()})
print("ort inference:", time.time() - start)첫 인퍼런스 속도가 영향을 줄까하여, 한번 inference를 한 후에 1000번 반복문을 돌리고 시간을 측정하였습니다.
출력 결과는 아래와 같습니다.

속도가 매우 많이 차이 나는 것을 확인 할 수 있습니다.
위의 테스트는 아래 이미지의 맥북 환경에서 테스트한 결과이며, 리눅스 서버에서는 이렇게 차이가 많이는 나지 않았는데 맥북에서 특히 차이가 많이 나는 것 같습니다.

onnxruntime을 활용하면, 속도가 빨라지는 장점 이외에도 크로스 플랫폼을 지원하므로, onnx로 변환한 모델을 다른 언어와 프레임워크 상에서 모델을 로딩하여 서빙 환경을 구성할 수 있습니다.
서버에서는 조금 아쉬운 파이썬의 약점을 보완할 수 있는 좋은 방법입니다.
그냥 파이썬에서 사용하시더라도, 속도에서도 이점을 가질 수 있으니 onnx 변환은 꼭 시도해보시는 것을 추천드립니다.
'ML OPS > Inference & Serving' 카테고리의 다른 글
| [MLOps, LLMOps] In-flight batching (0) | 2023.12.24 |
|---|---|
| [MLOps] BentoML - Adaptive Batching (0) | 2023.03.12 |
| [ML OPS] quantization을 활용한 인퍼런스 최적화 (ft. ONNX, TensorRT) (0) | 2022.07.23 |
| [ML OPS] transformers inference (ft. colab, onnx, gpu) (0) | 2022.07.10 |
| [ML OPS] 파이썬으로 딥러닝 모델 서빙하기 (ft. flask) (0) | 2022.02.08 |