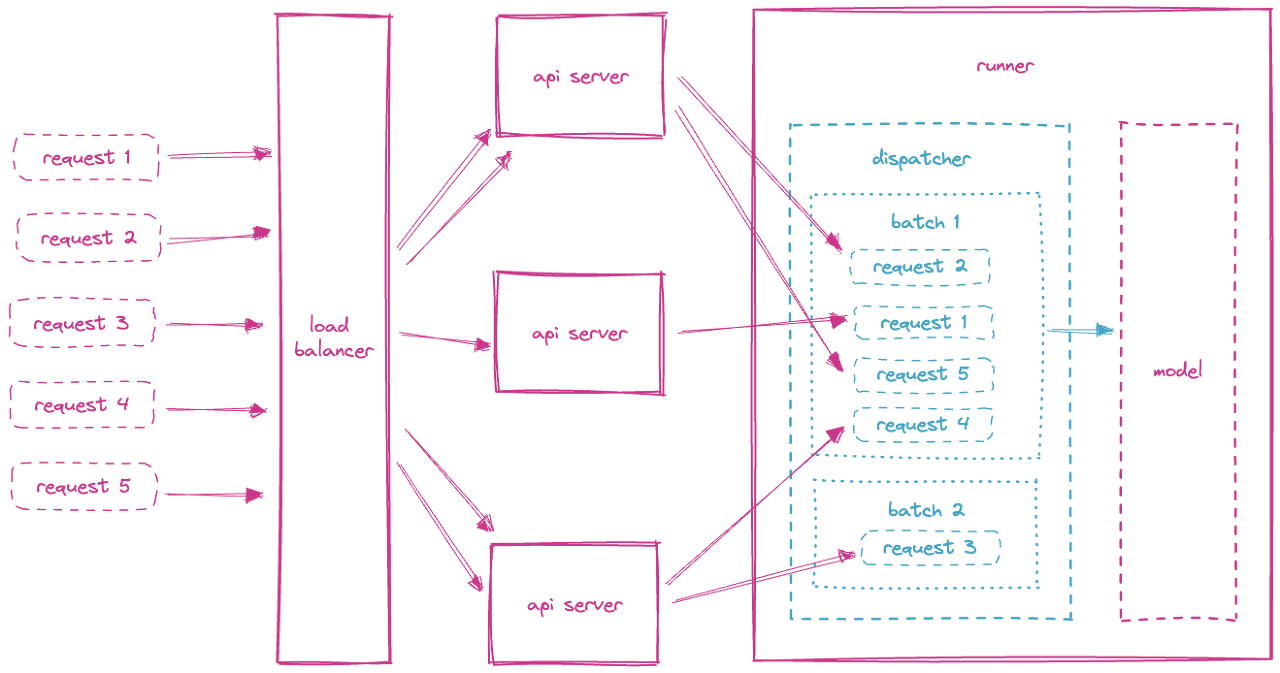
서빙에서 batch 최적화 기법으로 Adaptive batching을 소개한 적이 있습니다. https://seokhyun2.tistory.com/91 [MLOps] BentoML - Adaptive Batching 오늘은 Adaptive Batching에 대해서 알아보려고 합니다. 왜 필요한 지 먼저 알아볼건데, infernce의 경우 하나의 input을 inference 하는 것 보다, batch로 inference하면 훨씬 빠르고 효율적으로 추론을 할 수 있 seokhyun2.tistory.com Adaptive batching의 경우, 아래 이미지와 같이 batch 하나에 대해서 longest 기준에 맞춰 padding을 해서 inference를 하게 됩니다. Transformer의 encoder..