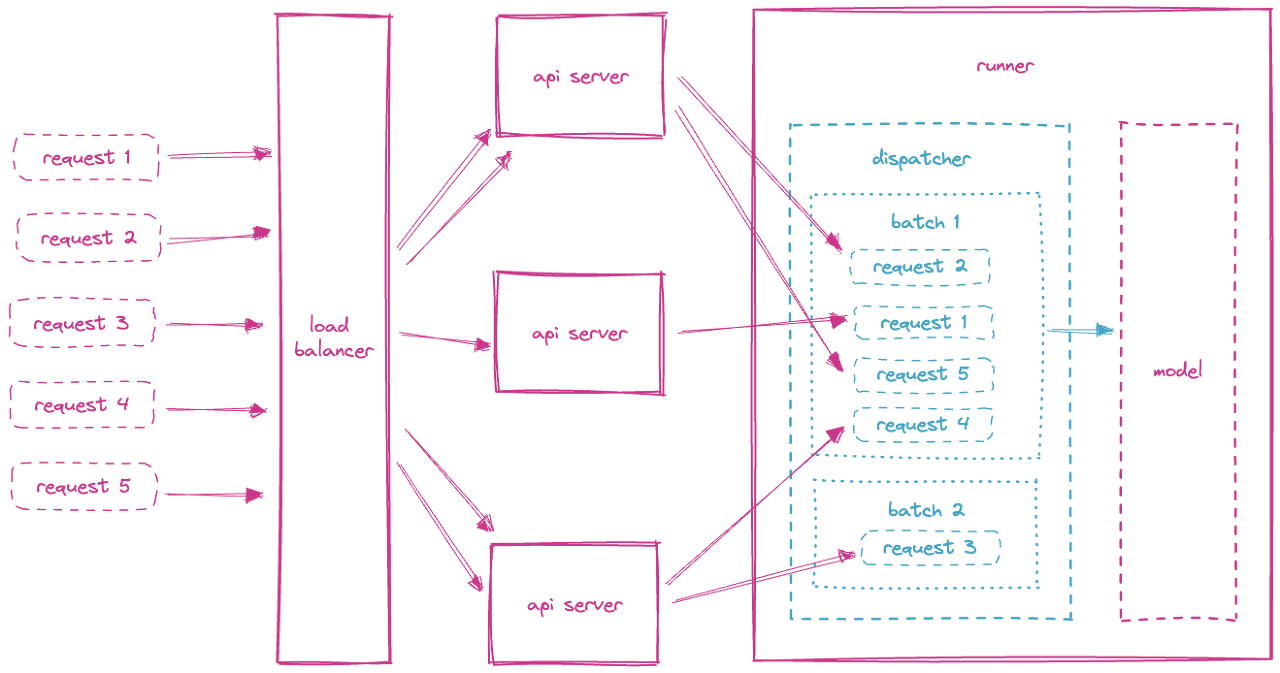
LLM(Large Language Model)이 발전하면서 RAG(Retrieval Augmented Generation)이 등장하였고, RAG의 방식 중에 하나로 벡터 서치가 굉장히 많이 활용되고 있습니다. 클라우드 서비스들도 벡터 서치를 지원하는 제품을 제공하고 있습니다. AWS는 Amazon OpenSearch Service, Azure는 Congnitive Search, GCP는 Vertex AI라는 제품을 각각 보유하고 있습니다. 오늘은 클라우드 중에 점유율이 제일 높은 AWS의 제품을 한번 리뷰해보려고 합니다. AWS가 제공하는 OpenSearch는 오픈 소스로도 제공되고 있어서, 꼭 AWS에서 사용할 필요는 없습니다. 직접 구축해서 사용하고 싶으시다면 아래 링크로 들어가서 문서를 읽어보고 구..